

I’m not a programmer by any stretch but what LLM’s have been great for is getting my homelab set up. I’ve even done some custom UI stuff for work that talks to open source backend things we run. I think I’ve actually learned a fair bit from the experience and if I had to start over I’d be able to do way way more on my own than I was able to when I first started. It’s not perfect and as others have mentioned I have broken things and had to start projects completely from scratch but the second time through I knew where pitfalls were and I’m getting better at knowing what to ask for and telling it what to avoid.
I’m not a programmer but I’m not trying to ship anything either. In general I’m a pretty anti-AI guy but for the non-initiated that want to get started with a homelab I’d say its damn near instrumental in a quick turnaround and a fairly decent educational tool.
This is the correct way to do it, use it, see if it works for you and try to understand what happened. It’s not that different from using examples or stack overflow. With time you get better, but you need to have that last critical thinking step. Otherwise you will never learn and will just copy paste hoping it works
As a programmer I’ve found it infinitely times more useful for troubleshooting and setting up things than for programming. When my Arch Linux nukes itself again I know I’ll use an LLM, when I find a random old device or game at the thrift store and want to get it to work I’ll use an LLM, etc. For programming I only use the IntelliJ line completion models since they’re smart enough to see patterns for the dumb busywork, but don’t try to outsmart me most of the time which would only cost more time.
lol it did save me from my first
rm -rf /
bro thought software engineering is just $20/mo chatgpt💀
They’re so close to actual understanding of how much they suck.
Obviously fake. Still funny though.
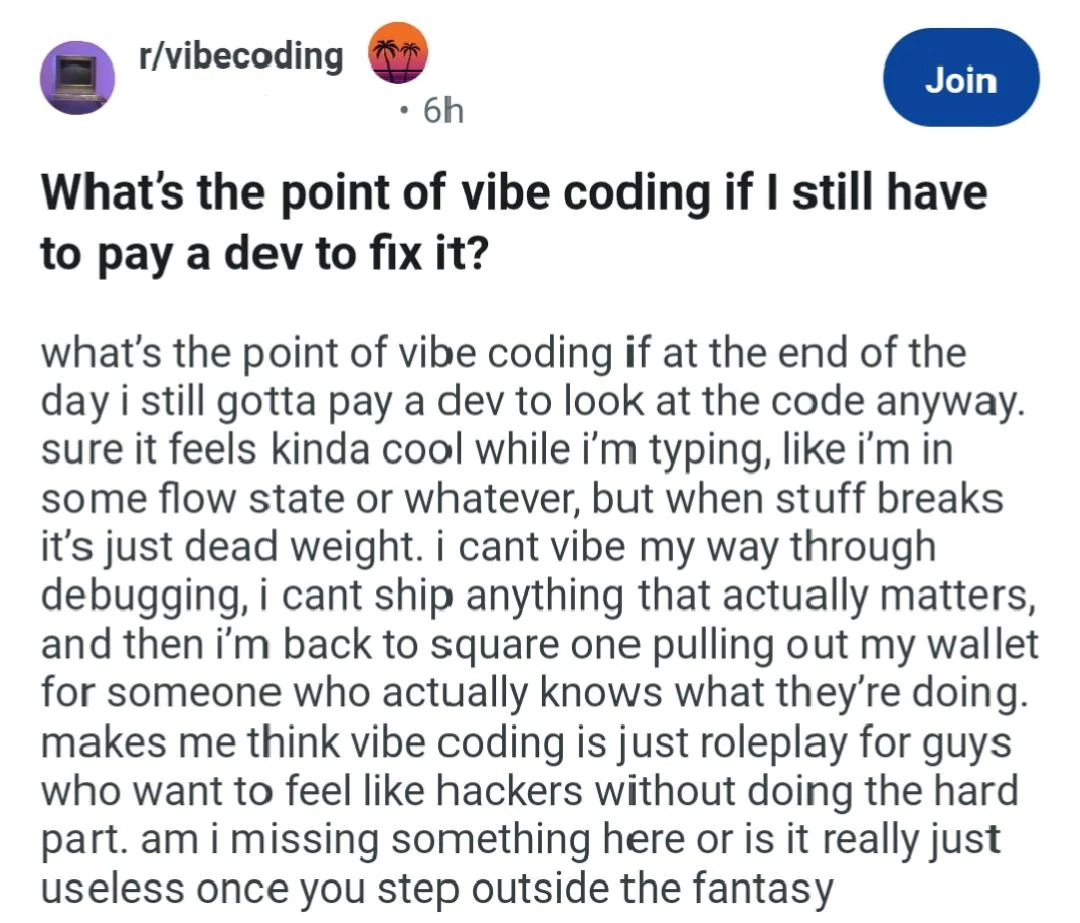
You should(n’t) watch Quin69. He’s currently “vibe-coding” a game with Claude. Already spent $3000 in tokens, and the game was in such a shit state, that a viewer had to intervene and push an update that dragged it to a “playable” state.
The game is at a level of a “my first godot game”, that someone who’s learning could’ve made over a weekend.
I better not watch this, it would make me angry. I hate people who could have hired someone like me for the same or even less money and get a working product. But no, they always throw money at fraudsters. Because wasting resources is their very nature.
I watched a bit out of curiosity and even vibe-coding aside, he is annoying as fuck. Couldn’t stand him 20 seconds.
Are you saying the comment is fake, or the sentiment? This was actually posted to reddit: https://archive.is/U9ntj
Fake in that it’s almost assuredly written and posted by someone who is actively anti-vibe coding and this is a troll on the true believers.
Correct.
I love the one guy on that thread who is defending vibe coding, and is “about to launch his first application,” and anyone who tells him how dumb he is is only doing so because they feel threatened.
Nah I’m on that guy’s side. His experience lines up with my own, namely that vibe coding is not useful for people who don’t know how to program, but it can be useful for people who do know how to program, and simply aren’t familiar with the specific syntax used in a language they’re not an expert in.
In that case, the queries to the AI model aren’t, “write me a program that can do X”, it’s more like “write me a function in this language that can take A, B, and C as inputs, do operation Y with them, and return Z”, or “what’s the best way to find all of the unique elements in an array and sort it alphabetically in this language”. Then the programmer can take those pieces and build up a proper application with them. The AI isn’t actually writing the program for you, it’s more like a customized Stack Overflow generator, without having to wade through a decade of people arguing back and forth in the comments about inane bullshit.
Does it save a ton of time? No, but it’s still helpful, and can get you up and running in a new language much faster than the alternative.
My company is doing a big push for LLM/codegen/“everyday ‘AI’”
Sorry - threw up in my mouth a little bit there
And pretty much the only thing I acquiesce to using is the “better autocomplete” feature. Most of the other stuff it seems to offer is essentially useless on a day-to-day basis for me.
And moreover, it’s actively harmful to the entire practice of engineering, because management and execs see it as this magical oracle/panopticon that can magically make people more productive and churn out 10x more bullshit products that they didn’t consult with engineers on than before. It can’t and it doesn’t. But that doesn’t stop them from thinking it can.
And then they stop hiring junior levels because “codegen can do that”. And then you have a generational gap in the entire fucking discipline of coding as an art, because the entire fucking tech industry is doing this. And we haven’t even touched on the ecological and infrastructural (as in: water and power, not “which cloud or bare metal do we put this on”) implications and how they’re being blatantly ignored and hand-waved away, or the comical license and usage violations that are perfectly fine when large companies do but you’ve been a naughty boy if you torrent a fucking movie. But I digress.
Is that what the weird extra width on some letters is, artifacts from some AI generating the post?
No, the text itself. No vibe coder would write something like that. The artifacts you mentioned are the result of simple horizontal and vertical upscaling. If you zoom in you can see it better.
No, the phrasing makes it clear someone wrote a fictional account of becoming self aware that the output of vibe coding isn’t maintainable as it scales.
I’m entirely too trusting and would like to know what about the phrasing tips you off that it’s fictional. Back on Reddit I remember so many claims about posts being fake and I was never able to tease out what distinguished the “omg fake! r/thathappened” posts from the ones that weren’t accused of that, and I feel this is a skill I should be able to have on some level. Although taking an amusing post that wasn’t real as real doesn’t always have bad consequences.
But I mostly asked because I’m curious about the weird extra width on letters.
When something is too “on the nose,” for example, it’s written in exactly the way that would induce the most cheering and virality because it appeals so much to one group of people, it’s worth considering it may have been written to provoke exactly that reaction.
Thanks!
I really wish people did not do this. This isn’t something I was ever taught to look for, and I like to think I got a good education. I was taught to make sure my source is credible, to consider biases and spin and what things are facts and what is just opinion, but I wasn’t taught to look for a lot of deception people call out online. But I guess I have to live with this and gain the skill to look for deception. Genuinely, thanks for helping me, since I don’t think I ever would have figured out what raises “fake” flags in most peoples’ heads on my own.
AmidFuror’s description is on point and I see it as a variant of Poe’s Law. Instead of sarcasm being mistaken for a real belief, it is presenting a fictional account of someone being self aware that is mistaken for someone actually becoming self aware.
There are two lines that make me absolutely certain it is written by someone who it not a vibe coder and is leaning into the sarcasm.
- ‘pulling out my wallet for someone that knows what they are doing’ implies the poster knows they don’t know what they are doing
- ‘vibe coding is just roleplaying for guys who want to feel like hackers’ is a joke I’ve seen directed at vibe coders more than once
Keep in mind that not all deception is malicious, but most people see the word deception as having a negative implication. An actor/actress pretending to be someone else is technically deceptive the same way as whoever wrote this hilarious post. They are presenting a fictional account for an audience.
r/thatHappened was the worst thing to happen to Reddit and I sincerely hate whoever created that sub
Interesting. Curious for a point of comparison how The Onion reads to you.
(Only a mediocre point of comparison I fear, but)
That’s a bit difficult because I already go into anything from The Onion knowing it’s intended to be humorous/satirical.
What I lack in ability to recognize satire or outright deception from posts written online, I make up for by reading comment threads: seeing people accuse things of being fake, seeing people defend it as true, seeing people point out the entire intention of a website is satire, seeing people who had a joke go over their heads get it explained… relying on the collective hivemind to help me out where I am deficient. It’s not a perfect solution at all, especially since people can judge wrong—I bet some “omg so fake” threads were actually real, and some astroturf-type things written to influence others without real experience behind it got through as real.
I refuse to believe this post isn’t satire, because holy shit.
If I was 14 and had an interest in coding, the promise of ‘vibe coding’ would absolutely reel me in. Most of us here on Lemmy are more tech savvy and older, so it’s easy to forget that we were asking Jeeves for .bat commands and borrowing* from Planet Source Code.
But yeah, it feels like satire. Haha.
Lol I remember when I was around pre-school / kindergarten age and I was asking family members how to spell words so I could type into a Windows 3.1 “run program” dialog box “make sonic game”.
I feel you, and I agree that as a learning tool that’s probably how it’s being used (whether that’s good or bad is a different topic), but the fact that they immediately talk about having to pay a dev makes it sound like someone who isn’t trying to learn but trying to make a product.

I don’t really care about vibe coders but as a dev with just under 2 decades in the field:
- Your vibe coding shit will not go to prod until humans fully review it
- You better review it yourself first before offloading that massive mental drain to someone else (which means you still need to have some semblance of programming skills). Don’t open a PR with 250 files in it and then tell someone else to validate it.
- Use more context. Don’t give it vague ass prompts.
- Don’t use auto-accept. That’s just lazy asshole shit.
I can’t stress this enough: if you give me a PR with tons of new files and expect me to review it when you didn’t even review it yourself, I will 100% reject it and make you do it. If it’s all dumped into a single commit, I will whip your computer into the nearest body of water and tell you to go fish it out.
I don’t care what AI tool wrote your code. You’re still responsible for it and I will blame you.
When I see a sloppy PR I remind people “AI didn’t write that. You wrote it. Your name is on the git blame.”
Love it, I have a vibe coding colleague I will use this with.
I like this mentality. I might start telling people the same thing
As a software developer, I’ve found some free LLMs to provide productivity boosts. It is a fairly hairpulling experience to not try too hard to get a bad LLM to correct itself, and learning to switch quickly from bad LLMs is a key skill in using them. A good model is still one that you can fix their broken code, and ask them to understand why what you provided them fixes it. They need a long context window to not repeat their mistakes. Qwen 3 is very good at this. Open source also means a future of customizing to domain, ie. language specific, optimizations, and privacy trust/unlimited use with enough local RAM, with some confidence that AI is working for you rather than data collecting for others. Claude Sonnet 4 is stronger, but limited free access.
The permanent side of high market cap US AI industry is that it will always be a vector for NSA/fascism empire supremacy, and Skynet goal, in addition to potentially stealing your input/output streams. The future for users who need to opt out of these threats, is local inference, and open source that can be customized to domains important to users/organizations. Open models are already at close parity, IMO from my investigations, and, relatively low hanging fruit, customization a certain path to exceeding parity for most applications.
No LLM can be trusted to allow you do to something you have no expertise in. This state will remain an optimistic future for longer than you hope.
I think the key to good LLM usage is a light touch. Let the LLM know what you want, maybe refine it if you see where the result went wrong. But if you find yourself deep in conversation trying to explain to the LLM why it’s not getting your idea, you’re going to wind up with a bad product. Just abandon it and try to do the thing yourself or get someone who knows what you want.
They get confused easily, and despite what is being pitched, they don’t really learn very well. So if they get something wrong the first time they aren’t going to figure it out after another hour or two.
In my experience, they’re better at poking holes in code than writing it, whether that’s green or brownfield.
I’ve tried to get it to make sections of changes for me, and it feels very productive, but when I time myself I find I spend probably more time correcting the LLM’s work than if I’d just written it myself.
But if you ask it to judge a refactor, then you might actually get one or two good points. You just have to really be careful to double check its assertions if you’re unfamiliar with anything, because it will lead you to some real boners if you just follow it blindly.
At work we’ve got coderabbit set up on our github and it has found bugs that I wrote. Sometimes the thing drives me insane with pointless comments, but just today found a spot that would have been a big bug in prod in like 3 months.
It is not useless. You should absolutely continue to vibes code. Don’t let a professional get involved at the ground floor. Don’t inhouse a professional staff.
Please continue paying me $200/hr for months on end debugging your Baby’s First Web App tier coding project long after anyone else can salvage it.
And don’t forget to tell your investors how smart you are by Vibes Coding! That’s the most important part. Secure! That! Series! B! Go public! Get yourself a billion dollar valuation on these projects!
Keep me in the good wine and the nice car! I love vibes coding.
Not me, I’d rather work on a clean code base without any slop, even if it pays a little less. QoL > TC
So there are multiple people in this thread who state their job is to unfuck what the LLMs are doing. I have a family member who graduated in CS a year ago and is having a hell of a time finding work, how would he go about getting one of these “clean up after the model” jobs?
Has he tried being a senior developer? He should really try being a senior developer.
Answer is probably the same as before AI: build a portfolio on GitHub. These days maybe try to find repos that have vibe code in them and make commits that fix the AI garbage.
Answer is probably the same as before AI: build a portfolio on GitHub
You really think that using GitHub falls in the usual vibecoding toolbox? As in: would they even know where/how to look?
You think vibe coders don’t love the smell of their own shit enough to show it to the world?
No idea, but I am not sure your family member is qualified. I would estimate that a coding LLM can code as well as a fresh CS grad. The big advantage that fresh grads have is that after you give them a piece of advice once or twice, they stop making that same mistake.
Where is this coming from? I don’t think an LLM can code at the level of a recent cs grad unless it’s piloted by a cs grad.
Maybe you’ve had much better luck than me, but coding LLMs seem largely useless without prior coding knowledge.
It makes me so mad that there are CS grads who can’t find work at the same time as companies are exploiting the H1B process saying “there aren’t enough applicants”. When are these companies going to be held accountable?
This is in no way new. 20 years ago I used to refer to some job postings as H1Bait because they’d have requirements that were physically impossible (like having 5 years experience with a piece of software <2 years old) specifically so they could claim they couldn’t find anyone qualified (because anyone claiming to be qualified was definitely lying) to justify an H1B for which they would be suddenly way less thorough about checking qualifications.
My entire IT career has been funded by morons like this. This is just the latest moronic idea that is going to pay my bills. Cleaning up after vibe coders has guaranteed my income until I die. You see, posts like this focus on the code that is broken and requires another dev to fix it enough to get it going. There is a long road from “finally working” to “production ready” to “optimized”, and we get paid along every inch of the way.
Why does this image look like an AI-generated screenshot? The letter spacing and weights are all wrong.
It’s a real post on Reddit. I don’t know what combination of screenshotting/uploading tools leads to this kind of mangling, but I’ve seen it in screenshots from Android, too. The artifacts seem to run down in straight vertical lines, so maybe slight scaling with a nearest-neighbor algorithm (in 2025?!?) plus a couple levels of JPEG compression? It looks really weird.
I’m curious. If anyone knows, please enlighten me!
Clearly satire
It’s kind of hard for me to tell on this one. Maybe the boomer lead is seeping into my brain.
Nah, it’s the microplastics.
Microplastics are stored in the balls.
Why not both ™?
With a pinch of PFAS for good measure?
What is good enough for the goose is good for the gander
But I thought armies of teenagers were starting tech businesses?!
My boss is literally convinced we can now basically make programs that take rockets to mars, and that it’s literally clicks away. For the life of me, it is impossible to convince him that this is, in fact, not the case. Whoever fired developers because ‘AI could do it’ is going to regret it.
Maybe try convincing him in terms he would understand. If it was really that good, it wouldn’t be public. They’d just use it internally to replace every proprietary piece of software in existence. They’d be shitting out their own browser, office suite, CAD, OS, etc. Microsoft would be screwing themselves by making chatgpt public. Microsoft could replace all the Adobe products and drive them out of business tomorrow.
Edit: that was fast










{kind=link}